Regularization Effects in Deep Learning Architecture
Keywords:
Deep learning, Regularization, Overfitting, Size, Epoch, Dropout, Weight Decay, AugmentationAbstract
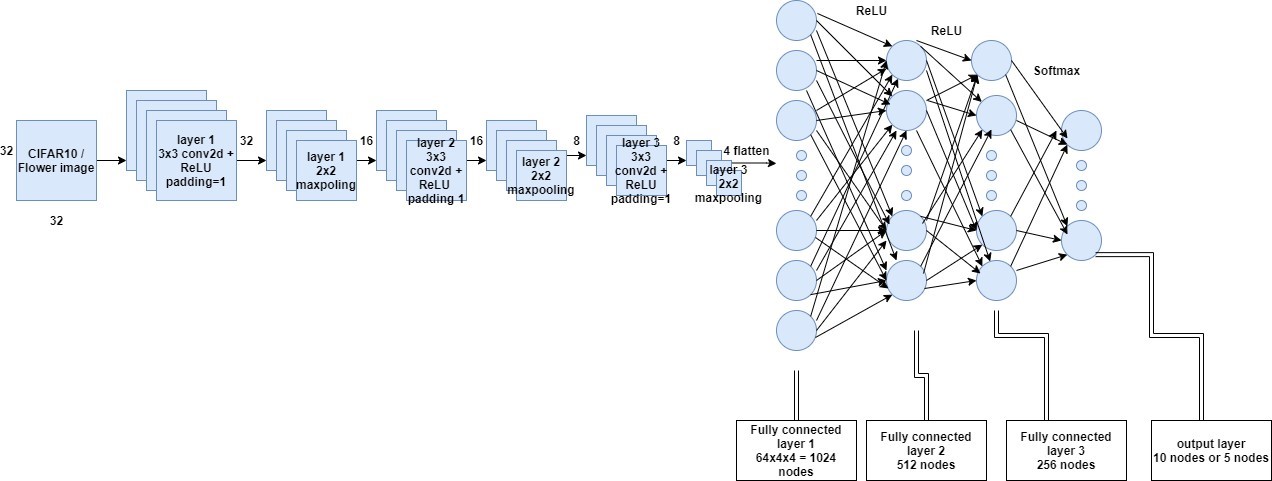
This research examines the impact of three widely utilized regularization approaches -- data augmentation, weight decay, and dropout --on mitigating overfitting, as well as various amalgamations of these methods. Employing a Convolutional Neural Network (CNN), the study assesses the performance of these strategies using two distinct datasets: a flower dataset and the CIFAR-10 dataset. The findings reveal that dropout outperforms weight decay and augmentation on both datasets. Additionally, a hybrid of dropout and augmentation surpasses other method combinations in effectiveness. Significantly, integrating weight decay with dropout and augmentation yields the best performance among all tested method blends. Analyses were conducted in relation to dataset size and convergence time (measured in epochs). Dropout consistently showed superior performance across all dataset sizes, while the combination of dropout and augmentation was the most effective across all sizes, and the triad of weight decay, dropout, and augmentation excelled over other combinations. The epoch-based analysis indicated that the effectiveness of certain techniques scaled with dataset size, with varying results.
Published
How to Cite
Issue
Section
Copyright (c) 2024 Muhammad Dahiru Liman, Salamatu Ibrahim Osanga, Esther Samuel Alu, Sa'adu Zakariya

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite
Similar Articles
- L. G. Salaudeen, D. GABI, M. Garba, H. U. Suru, Deep convolutional neural network based synthetic minority over sampling technique: a forfending model for fraudulent credit card transactions in financial institution , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 2, May 2024
- Dekera Kenneth Kwaghtyo, Christopher Ifeanyi Eke, Timothy Moses, CropGAN: A conditional GAN framework for synthetic tabular data augmentation in crop recommendation systems , Journal of the Nigerian Society of Physical Sciences: Volume 8, Issue 3, August 2026 (In Progress)
- F. U. Salifu, O. A. Oladipo, E. O. Ebock, B. Nava, Deep neural network model for vertical total electron content prediction at a single low latitude station , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- Shaymaa Mohammed Ahmed, Majid Khan Majahar Ali, Raja Aqib Shamim, Integrating robust feature selection with deep learning for ultra-high-dimensional survival analysis in renal cell carcinoma , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- Emmanuel Gbenga Dada, Aishatu Ibrahim Birma, Abdulkarim Abbas Gora, Ensemble machine learning algorithm for cost-effective and timely detection of diabetes in Maiduguri, Borno State , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 4, November 2024
- Santosh Kumar Upadhyay, Rajesh Prasad, Efficient-ViT B0Net: A high-performance light weight transformer for rice leaf disease recognition and classification , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- O. Oderinde, C. L. Mgbechidinma, A. O. Agbeja, A. A. Ajayi, A. O. Ogundiran, O. O. Olaide, O. A. Orelaja, C. A. Mgbechidimma, C. O. Ajanaku, K. D. Oyeyemi, Appraising raw exhaust pollutant gases emissions from industrial generators using statistics and machine learning approaches , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- V Umarani, A Julian, J Deepa, Sentiment Analysis using various Machine Learning and Deep Learning Techniques , Journal of the Nigerian Society of Physical Sciences: Volume 3, Issue 4, November 2021
- S. I. Ele, U. R. Alo, H. F. Nweke, A. H. Okemiri, E. O. Uche-Nwachi, Deep convolutional neural network (DCNN)-based model for pneumonia detection using chest x-ray images , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 2, May 2025
- A. E. Ibor, D. O. Egete, A. O. Otiko, D. U. Ashishie, Detecting network intrusions in cyber-physical systems using deep autoencoder-based dimensionality reduction approach anddeep neural networks , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
You may also start an advanced similarity search for this article.