
Performance Study of N-grams in the Analysis of Sentiments
Keywords:
ngrams, economic texts, machine learning, deep learning, sentiment analysisAbstract
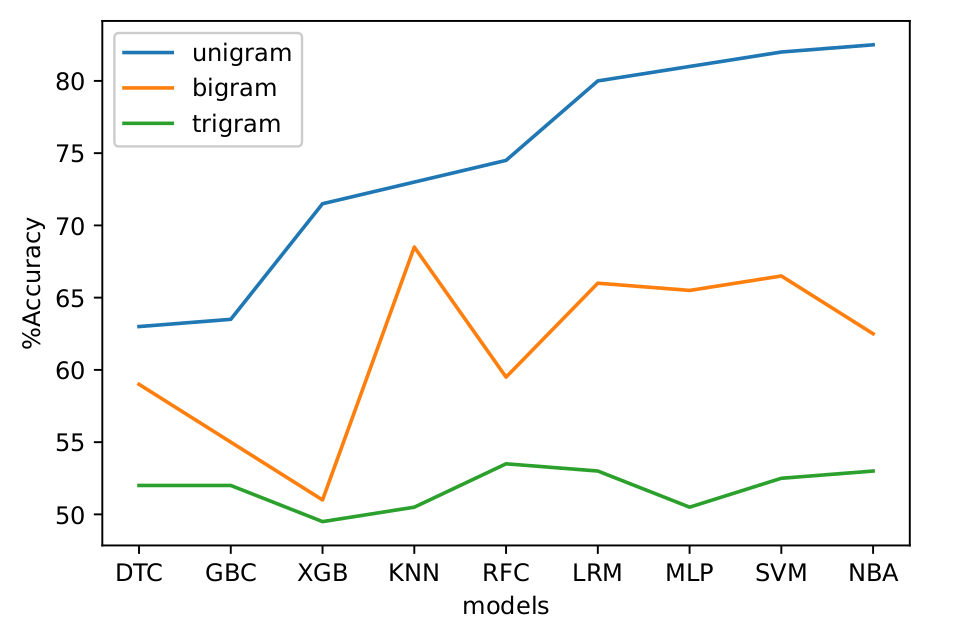
In this work, a study investigation was carried out using n-grams to classify sentiments with different machine learning and deep learning methods. We used this approach, which combines existing techniques, with the problem of predicting sequence tags to understand the advantages and problems confronted with using unigrams, bigrams and trigrams to analyse economic texts. Our study aims to fill the gap by evaluating the performance of these n-grams features on different texts in the economic domain using nine sentiment analysis techniques and found more insights. We show that by comparing the performance of these features on different datasets and using multiple learning techniques, we extracted useful intelligence. The evaluation involves assessing the precision, recall, f1-score and accuracy of the function output of the several machine learning algorithms proposed. The methods were tested using Amazon, IMDB, Reuters, and Yelp economic review datasets and our comprehensive experiment shows the effectiveness of n-grams in the analysis of sentiments.
Published
How to Cite
Issue
Section
Copyright (c) 2021 Journal of the Nigerian Society of Physical Sciences

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite
Similar Articles
- V Umarani, A Julian, J Deepa, Sentiment Analysis using various Machine Learning and Deep Learning Techniques , Journal of the Nigerian Society of Physical Sciences: Volume 3, Issue 4, November 2021
- S. N. Enemuo, O. N. Akande, M. O. Lawrence, I. C. Saidu, Optimized aspect level sentiment analysis of tweet data using deep learning and rule-based techniques , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 2, May 2025
- S. I. Ele, U. R. Alo, H. F. Nweke, A. H. Okemiri, E. O. Uche-Nwachi, Deep convolutional neural network (DCNN)-based model for pneumonia detection using chest x-ray images , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 2, May 2025
- Akila Dabara Kayit, Mohd Tahir Ismail, Novel way to predict stock movements using multiple models and comprehensive analysis: leveraging voting meta-ensemble techniques , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 3, August 2024
- Unyime Ufok Ibekwe, Uche M. Mbanaso, Nwojo Agwu Nnanna, Umar Adam Ibrahim, A machine learning sentiment classification of factors that shape trust in smart contracts , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 1, February 2025
- Muhammad Dahiru Liman, Salamatu Ibrahim Osanga, Esther Samuel Alu, Sa'adu Zakariya, Regularization Effects in Deep Learning Architecture , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 2, May 2024
- Nahid Salma, Majid Khan Majahar Ali, Raja Aqib Shamim, Machine learning-based feature selection for ultra-high-dimensional survival data: a computational approach , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Gabriel James, Ime Umoren, Anietie Ekong, Saviour Inyang, Oscar Aloysius, Analysis of support vector machine and random forest models for classification of the impact of technostress in covid and post-covid era , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 3, August 2024
- George Muddu, Shefiu Olusegun Ganiyu, Adekunle Olugbenga Ejidokun, Yusuf Abass Aleshinloye, Integrated data-driven credit default prediction in Uganda using machine learning models , Journal of the Nigerian Society of Physical Sciences: Volume 8, Issue 1, February 2026
- David Opeoluwa Oyewola, Emmanuel Gbenga Dada, Juliana Ngozi ndunagu, Terrang Abubakar Umar, Akinwunmi S.A, COVID-19 Risk Factors, Economic Factors, and Epidemiological Factors nexus on Economic Impact: Machine Learning and Structural Equation Modelling Approaches , Journal of the Nigerian Society of Physical Sciences: Volume 3, Issue 4, November 2021
You may also start an advanced similarity search for this article.



