A feature selection and scoring scheme for dimensionality reduction in a machine learning task
Keywords:
Algorithm, Dataset, Dimensionality reduction, Feature selectionAbstract
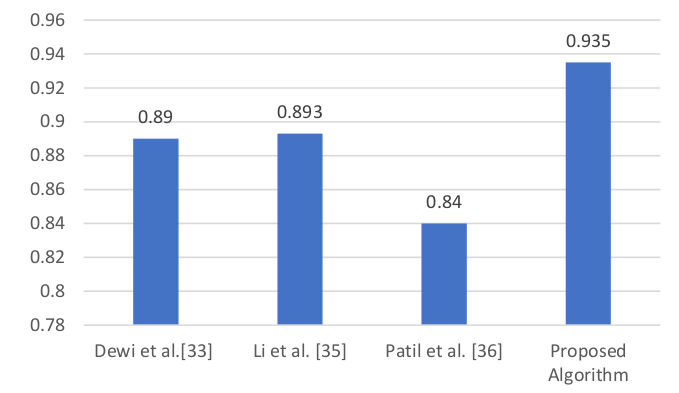
Selection of important features is very vital in machine learning tasks involving high-dimensional dataset with large features. It helps in reducing the dimensionality of a dataset and improving model performance. Most of the feature selection techniques have restriction in the kind of dataset to be used. This study proposed a feature selection technique that is based on statistical lift measure to select important features from a dataset. The proposed technique is a generic approach that can be used in any binary classification dataset. The technique successfully determined the most important feature subset and outperformed the existing techniques. The proposed technique was tested on lungs cancer dataset and happiness classification dataset. The effectiveness of the proposed technique in selecting important features subset was evaluated and compared with other existing techniques, namely Chi-Square, Pearson Correlation and Information Gain. Both the proposed and the existing techniques were evaluated on five machine learning models using four standard evaluation metrics such as accuracy, precision, recall and F1-score. The experimental results of the proposed technique on lung cancer dataset shows that logistic regression, decision tree, adaboost, gradient boost and random forest produced a predictive accuracy of 0.919%, 0.935%, 0.919%, 0.935% and 0.935% respectively, and that of happiness classification dataset produced a predictive accuracy of 0.758%, 0.689%, 0.724%, 0.655% and 0.689% on random forest, k-nearest neighbor, decision tree, gradient boost and cat boost respectively, which outperformed the existing techniques.
Published
How to Cite
Issue
Section
Copyright (c) 2024 Philemon Uten Emmoh, Christopher Ifeanyi Eke, Timothy Moses

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite
Similar Articles
- Oluwaseun IGE, Keng Hoon Gan, Ensemble feature selection using weighted concatenated voting for text classification , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 1, February 2024
- A. B Yusuf, R. M Dima, S. K Aina, Optimized Breast Cancer Classification using Feature Selection and Outliers Detection , Journal of the Nigerian Society of Physical Sciences: Volume 3, Issue 4, November 2021
- Ebere Uzoka Chidi, Edward Anoliefo, Collins Udanor, Asogwa Tochukwu Chijindu, Lois Onyejere Nwobodo, A blind navigation guide model for obstacle avoidance using distance vision estimation based YOLO-V8n , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 1, February 2025
- Shaymaa Mohammed Ahmed, Majid Khan Majahar Ali, Raja Aqib Shamim, Integrating robust feature selection with deep learning for ultra-high-dimensional survival analysis in renal cell carcinoma , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- Mokhtar Ali, Abdelkerim Souahlia, Abdelhalim Rabehi, Mawloud Guermoui, Ali Teta, Imad Eddine Tibermacine, Abdelaziz Rabehi, Mohamed Benghanem , A robust deep learning approach for photovoltaic power forecasting based on feature selection and variational mode decomposition , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Christian N. Nwaeme, Adewale F. Lukman, Robust hybrid algorithms for regularization and variable selection in QSAR studies , Journal of the Nigerian Society of Physical Sciences: Volume 5, Issue 4, November 2023
- Kenneth Christopher Ugwoke, Nnanna Nwojo Agwu, Saleh Abdullahi, Artificial potential field path length reduction using Kenneth-Nnanna-Saleh algorithm , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- A. E. Ibor, D. O. Egete, A. O. Otiko, D. U. Ashishie, Detecting network intrusions in cyber-physical systems using deep autoencoder-based dimensionality reduction approach anddeep neural networks , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Emmanuel Gbenga Dada, Aishatu Ibrahim Birma, Abdulkarim Abbas Gora, Ensemble machine learning algorithm for cost-effective and timely detection of diabetes in Maiduguri, Borno State , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 4, November 2024
- Gabriel James, Anietie Ekong, Etimbuk Abraham, Enobong Oduobuk, Peace Okafor, Analysis of support vector machine and random forest models for predicting the scalability of a broadband network , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 3, August 2024
You may also start an advanced similarity search for this article.
Most read articles by the same author(s)
- Dekera Kenneth Kwaghtyo, Christopher Ifeanyi Eke, Timothy Moses, CropGAN: A conditional GAN framework for synthetic tabular data augmentation in crop recommendation systems , Journal of the Nigerian Society of Physical Sciences: Volume 8, Issue 3, August 2026 (In Progress)