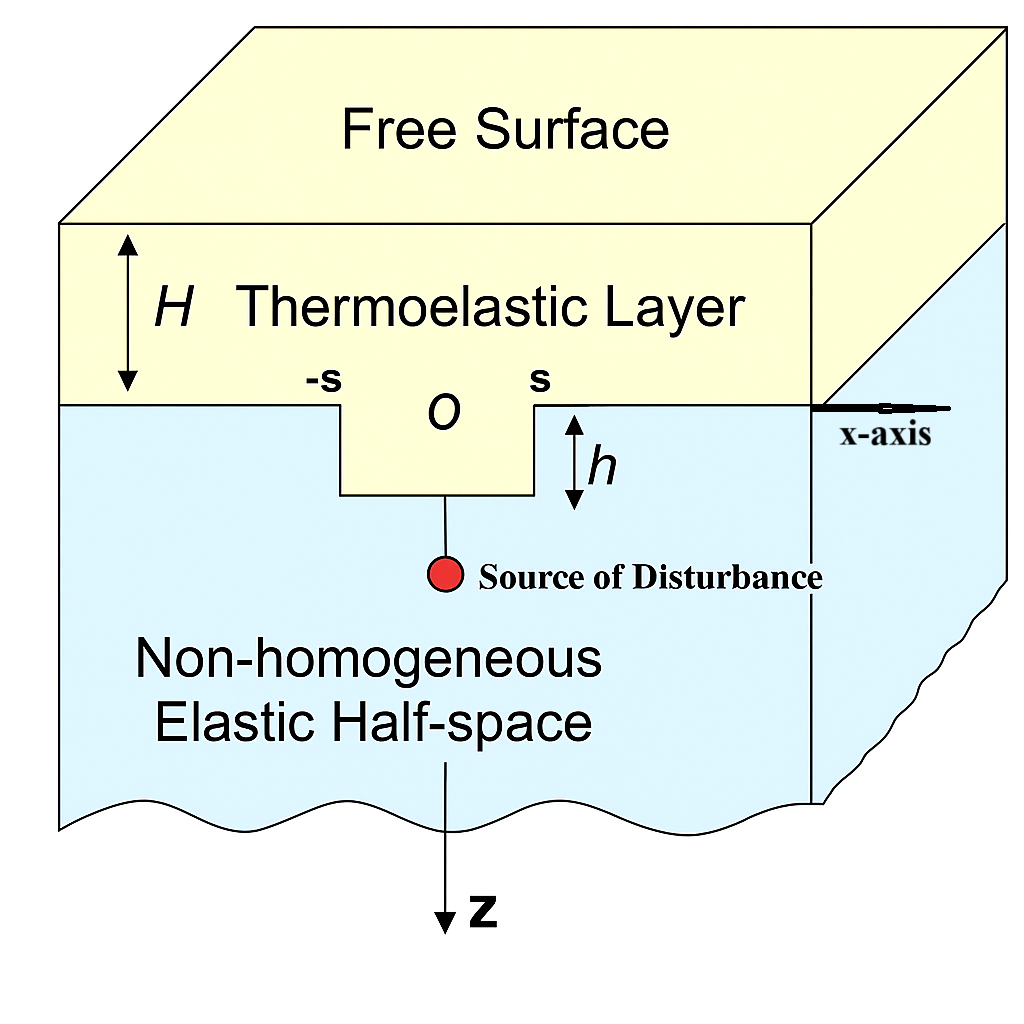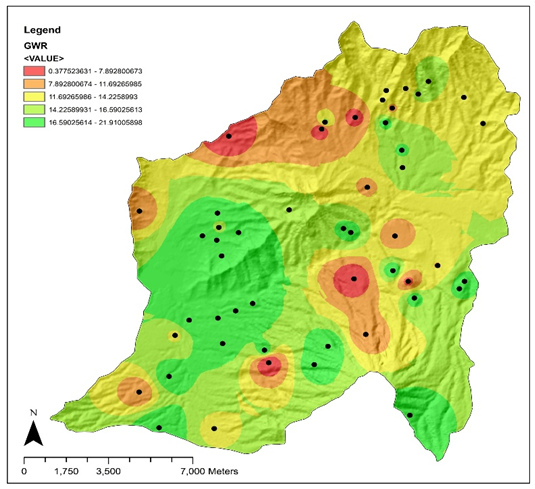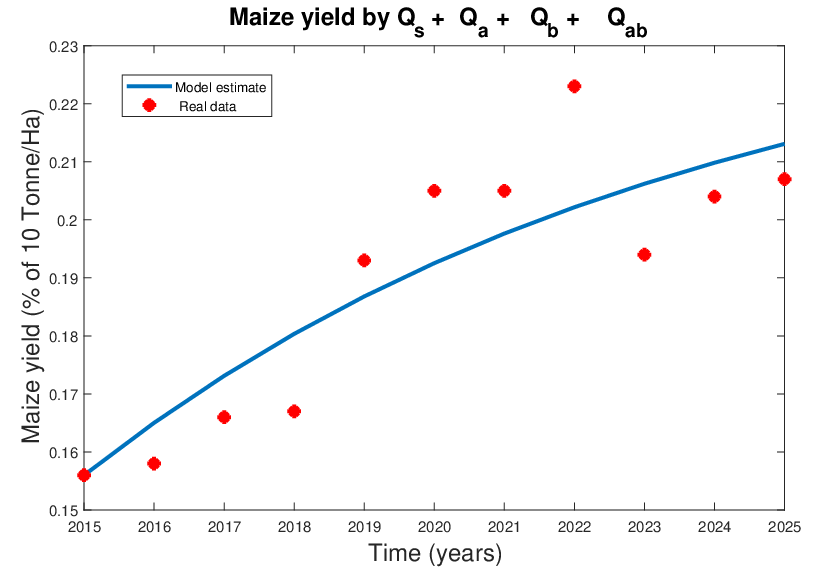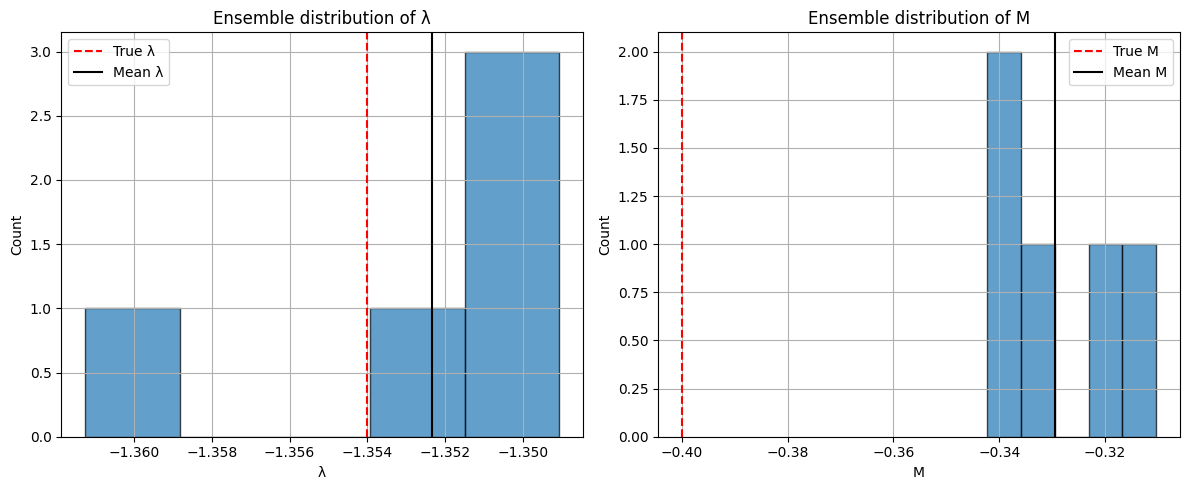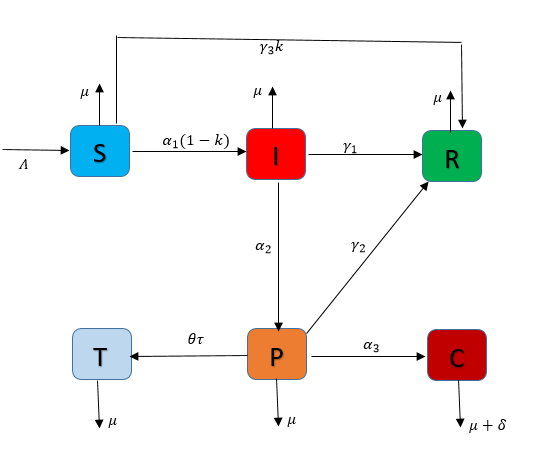
Journal of the Nigerian Society of Physical Sciences (JNSPS) is a peer-reviewed journal published quarterly (February, May, August, and November) by the Nigerian Society of Physical Sciences. It offers an exciting publication outlet for Physical Science reports. It covers all areas of Physical Sciences which includes:
- Chemistry
- Computer Science
- Mathematics & Statistics
- Physics & Astronomy
- Earth Sciences
Why Publish With JNSPS
We are committed to supporting you throughout your publishing “journey” – from submission, through peer review, to publication and promotion
Open Access
JNSPS is a strong supporter of open access (OA). All the research articles published in JNSPS are fully open access.
Read moreRefereed
Peer review process - Committed to serving the scientific community. JNSPS uses a single-blind peer-review process.
Read more100,000 NGN
APC is 100,000 NGN as an active Nigerian member of NSPS. Non-member/non-active member of NSPS pays 300 USD or its Naira equivalence
Read more