Identifying heterogeneity for increasing the prediction accuracy of machine learning models
Keywords:
Machine learning, Agriculture, Variable Selection, seaweed, heterogeneityAbstract
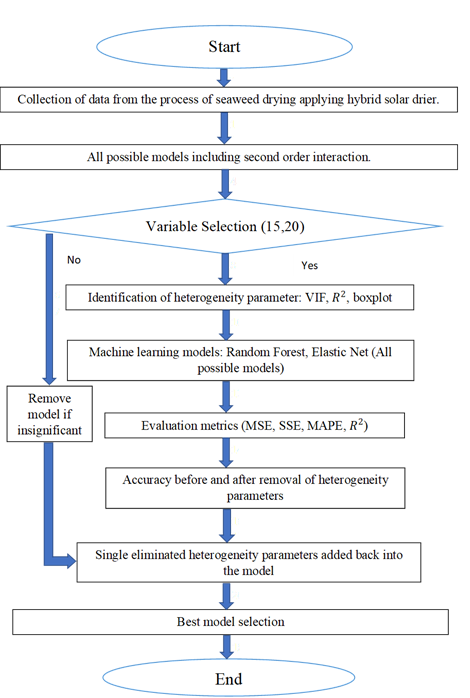
In recent years, the significance of machine learning in agriculture has surged, particularly in post-harvest monitoring for sustainable aquaculture. Challenges like heterogeneity, irrelevant variables and multicollinearity hinder the implementation of smart monitoring systems. However, this study focuses on investigating heterogeneity among drying parameters that determine the moisture content removal during seaweed drying due to its limited attention, particularly within the field of agriculture. Additionally, a heterogeneity model within machine learning algorithms is proposed to enhance accuracy in predicting seaweed moisture content removal, both before and after the removal of heterogeneity parameters and also after the inclusion of single-eliminated heterogeneity parameters. The dataset consists of 1914 observations with 29 independent variables, but this study narrows down to five: Temperature (T1, T4, T7), Humidity (H5), and Solar Radiation (PY). These variables are interacted up to second-order interactions, resulting in 55 variables. Variance inflation factor and boxplots are employed to identify heterogeneity parameters. Two predictive machine learning models, namely random forest and elastic net are then utilized to identify the 15 and 20 highest important parameters for seaweed moisture content removal. Evaluation metrics (MSE, SSE, MAPE, and R-squared) are used to assess model performance. Results demonstrate that the random forest model outperforms the elastic net model in terms of higher accuracy and lower error, both before and after removing heterogeneity parameters, and even after reintroducing single-eliminated heterogeneity parameters. Notably, the random forest model exhibits higher accuracy before excluding heterogeneity parameters.
Published
How to Cite
Issue
Section
Copyright (c) 2024 Paavithashnee Ravi Kumar, Majid Khan Majahar Ali, Olayemi Joshua Ibidoja

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite
Similar Articles
- Nour Hamad Abu Afouna, Majid Khan Majahar Ali, Optimizing precision farming: enhancing machine learning efficiency with robust regression techniques in high-dimensional data , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 1, February 2025
- Gabriel James, Ifeoma Ohaeri, David Egete, John Odey, Samuel Oyong, Enefiok Etuk, Imeh Umoren, Ubong Etuk, Aloysius Akpanobong, Anietie Ekong, Saviour Inyang, Chikodili Orazulume, A fuzzy-optimized multi-level random forest (FOMRF) model for the classification of the impact of technostress , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- O. J. Ibidoja, F. P. Shan, Mukhtar, J. Sulaiman, M. K. M. Ali, Robust M-estimators and Machine Learning Algorithms for Improving the Predictive Accuracy of Seaweed Contaminated Big Data , Journal of the Nigerian Society of Physical Sciences: Volume 5, Issue 1, February 2023
- Christian N. Nwaeme, Adewale F. Lukman, Robust hybrid algorithms for regularization and variable selection in QSAR studies , Journal of the Nigerian Society of Physical Sciences: Volume 5, Issue 4, November 2023
- Nahid Salma, Majid Khan Majahar Ali, Raja Aqib Shamim, Machine learning-based feature selection for ultra-high-dimensional survival data: a computational approach , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Timothy Kayode Samson, Francis Olatunbosun Aweda, Wind speed prediction in some major cities in Africa using Linear Regression and Random Forest algorithms , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 4, November 2024
- Oluwaseun IGE, Keng Hoon Gan, Ensemble feature selection using weighted concatenated voting for text classification , Journal of the Nigerian Society of Physical Sciences: Volume 6, Issue 1, February 2024
- Philemon Uten Emmoh, Christopher Ifeanyi Eke, Timothy Moses, A feature selection and scoring scheme for dimensionality reduction in a machine learning task , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 1, February 2025
- A. B Yusuf, R. M Dima, S. K Aina, Optimized Breast Cancer Classification using Feature Selection and Outliers Detection , Journal of the Nigerian Society of Physical Sciences: Volume 3, Issue 4, November 2021
- Dekera Kenneth Kwaghtyo, Christopher Ifeanyi Eke, Timothy Moses, CropGAN: A conditional GAN framework for synthetic tabular data augmentation in crop recommendation systems , Journal of the Nigerian Society of Physical Sciences: Volume 8, Issue 3, August 2026 (In Progress)
You may also start an advanced similarity search for this article.
Most read articles by the same author(s)
- O. J. Ibidoja, F. P. Shan, Mukhtar, J. Sulaiman, M. K. M. Ali, Robust M-estimators and Machine Learning Algorithms for Improving the Predictive Accuracy of Seaweed Contaminated Big Data , Journal of the Nigerian Society of Physical Sciences: Volume 5, Issue 1, February 2023
- Shaymaa Mohammed Ahmed, Majid Khan Majahar Ali, Raja Aqib Shamim, Integrating robust feature selection with deep learning for ultra-high-dimensional survival analysis in renal cell carcinoma , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- Xiaojie Zhou, Majid Khan Majahar Ali, Farah Aini Abdullah, Lili Wu, Ying Tian, Tao Li, Kaihui Li, Air quality prediction enhanced by a CNN-LSTM-Attention model optimized with an advanced dung beetle algorithm , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Ibrahim Adamu Mohammed, Majid Khan Majahar Ali, Sani Rabiu, Raja Aqib Shamim, Shahida Shahnawaz, Development and validation of hybrid drying kinetics models with finite element method integration for black paper in a v-groove solar dryer , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 4, November 2025
- Raja Aqib Shamim, Majid Khan Majahar Ali, Optimizing discrete dutch auctions with time considerations: a strategic approach for lognormal valuation distributions , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 1, February 2025
- Nahid Salma, Majid Khan Majahar Ali, Raja Aqib Shamim, Machine learning-based feature selection for ultra-high-dimensional survival data: a computational approach , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Shaymaa Mohammed Ahmed, Majid Khan Majahar Ali, Arshad Hameed Hasan, Evaluating feature selection methods in a hybrid Weibull Freund-Cox proportional hazards model for renal cell carcinoma , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 3, August 2025
- Chuchu Liang, Majid Khan Majahar Ali, Lili Wu, A novel multi-class classification method for arrhythmias using Hankel dynamic mode decomposition and long short-term memory networks , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 2, May 2025
- Raja Aqib Shamim, Majid Khan Majahar Ali, Mohamed Farouk Haashir bin Hamdullah, Computational optimization of auctioneer revenue in modified discrete Dutch auctions with cara risk preferences , Journal of the Nigerian Society of Physical Sciences: Volume 8, Issue 1, February 2026
- xiaojie zhou, Majid Khan Majahar Ali, Farah Aini Abdullah, Lili Wu, Ying Tian, Tao Li, Kaihui Li, Implementing a dung beetle optimization algorithm enhanced with multi-strategy fusion techniques , Journal of the Nigerian Society of Physical Sciences: Volume 7, Issue 2, May 2025